100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、重构(pd.merge、pd.concat、stack、unstack)

文章目录
- 每篇前言
- 一、数据连接(pd.merge)
- 1. left、right
- 2. how
- 3. on
- 4. left_on、right_on
- 5. sort
- 6. suffixes
- 7. left_index、right_index
- 二、数据合并(pd.concat)
- 1. index 没有重复的情况
- 2. index 有重复的情况
- 3. DataFrame合并时同时查看行索引和列索引有无重复
- 三、数据重构
- 1. stack
- 2. unstack
每篇前言
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
一、数据连接(pd.merge)
根据单个或多个键将不同DataFrame的行连接起来,类似数据库的连接操作
语法格式:
pd.merge(
left: DataFrame | Series,
right: DataFrame | Series,
how: str = "inner",
on: IndexLabel | None = None,
left_on: IndexLabel | None = None,
right_on: IndexLabel | None = None,
left_index: bool = False,
right_index: bool = False,
sort: bool = False,
suffixes: Suffixes = ("_x", "_y"),
copy: bool = True,
indicator: bool = False,
validate: str | None = None,
)
实例代码:
import pandas as pd
import numpy as np
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2' : np.random.randint(0,10,3)})
print(df_obj1)
print(df_obj2)
运行结果:
key data1
0 b 6
1 b 8
2 a 4
3 c 4
4 a 6
5 a 3
6 b 6
key data2
0 a 9
1 b 3
2 d 0
参数说明:
1. left、right
默认将重叠列的列名作为“外键”进行连接
示例代码:
# 默认将重叠列的列名作为“外键”进行连接
print(pd.merge(df_obj1, df_obj2))
运行结果:
key data1 data2
0 b 9 1
1 b 4 1
2 b 1 1
3 a 0 7
4 a 1 7
5 a 5 7
2. how
指定连接方式,默认是"inner"内连接。还可以选择:outer、left、right。
(1)内连接inner:
print(pd.merge(df_obj1, df_obj2, how='inner'))
运行结果:
key data1 data2
0 b 5 3
1 b 9 3
2 b 6 3
3 a 7 9
4 a 1 9
5 a 2 9
(2)外连接outer:
print(pd.merge(df_obj1, df_obj2, how='outer'))
运行结果:
key data1 data2
0 b 9.0 5.0
1 b 8.0 5.0
2 b 9.0 5.0
3 a 2.0 1.0
4 a 9.0 1.0
5 a 6.0 1.0
6 c 1.0 NaN
7 d NaN 4.0
(3)左连接left:
print(pd.merge(df_obj1, df_obj2, how='left'))
运行结果:
key data1 data2
0 b 8 6.0
1 b 6 6.0
2 a 3 5.0
3 c 2 NaN
4 a 7 5.0
5 a 5 5.0
6 b 3 6.0
(4)右连接right:
key data1 data2
0 a 0.0 2
1 a 4.0 2
2 a 5.0 2
3 b 7.0 6
4 b 8.0 6
5 b 3.0 6
6 d NaN 9
3. on
显示指定“外键”
# on显示指定“外键”
print(pd.merge(df_obj1, df_obj2, on='key'))
运行结果:
key data1 data2
0 b 0 1
1 b 0 1
2 b 5 1
3 a 2 4
4 a 0 4
5 a 2 4
4. left_on、right_on
left_on,左侧数据的“外键”,right_on,右侧数据的“外键”,默认是“内连接”(inner),即结果中的键是交集
# 更改列名
df_obj1 = df_obj1.rename(columns={'key':'key1'})
df_obj2 = df_obj2.rename(columns={'key':'key2'})
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2'))
运行结果:
data1 key1 data2 key2
0 8 b 0 b
1 8 b 0 b
2 6 b 0 b
3 3 a 9 a
4 4 a 9 a
5 9 a 9 a
5. sort
排序,接收True或False
6. suffixes
处理重复列名,默认为_x, _y
import pandas as pd
import numpy as np
# 处理重复列名
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data': np.random.randint(0, 10, 7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data': np.random.randint(0, 10, 3)})
print(pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right')))
运行结果:
key data_left data_right
0 b 3 1
1 b 6 1
2 b 4 1
3 a 8 1
4 a 0 1
5 a 8 1
7. left_index、right_index
按索引连接,left_index=True或right_index=True
import pandas as pd
import numpy as np
# 按索引连接
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'data2' : np.random.randint(0,10,3)}, index=['a', 'b', 'd'])
print(pd.merge(df_obj1, df_obj2, left_on='key', right_index=True))
运行结果:
key data1 data2
0 b 5 4
1 b 2 4
6 b 0 4
2 a 0 7
4 a 5 7
5 a 1 7
二、数据合并(pd.concat)
沿轴方向将多个对象合并到一起
语法格式:
pd.concat(
objs: Iterable[NDFrame] | Mapping[Hashable, NDFrame],
axis=0,
join="outer",
ignore_index: bool = False,
keys=None,
levels=None,
names=None,
verify_integrity: bool = False,
sort: bool = False,
copy: bool = True,
) -> FrameOrSeriesUnion:
1. index 没有重复的情况
import pandas as pd
import numpy as np
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(0,5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(5,9))
ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(9,12))
# print(ser_obj1)
# print(ser_obj2)
# print(ser_obj3)
# 不指定轴
print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
# 指定轴
print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1))
运行结果:
0 9
1 0
2 3
3 2
4 9
5 0
6 3
7 2
8 9
9 8
10 5
11 7
dtype: int32
0 1 2
0 9.0 NaN NaN
1 0.0 NaN NaN
2 3.0 NaN NaN
3 2.0 NaN NaN
4 9.0 NaN NaN
5 NaN 0.0 NaN
6 NaN 3.0 NaN
7 NaN 2.0 NaN
8 NaN 9.0 NaN
9 NaN NaN 8.0
10 NaN NaN 5.0
11 NaN NaN 7.0
2. index 有重复的情况
# index 有重复的情况
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(4))
ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(3))
# print(ser_obj1)
# print(ser_obj2)
# print(ser_obj3)
print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
运行结果:
0 9
1 4
2 2
3 6
4 9
0 9
1 9
2 6
3 9
0 3
1 1
2 2
dtype: int32
3. DataFrame合并时同时查看行索引和列索引有无重复
示例代码:
df_obj1 = pd.DataFrame(np.random.randint(0, 10, (3, 2)), index=['a', 'b', 'c'],
columns=['A', 'B'])
df_obj2 = pd.DataFrame(np.random.randint(0, 10, (2, 2)), index=['a', 'b'],
columns=['C', 'D'])
# print(df_obj1)
# print(df_obj2)
print(pd.concat([df_obj1, df_obj2]))
print(pd.concat([df_obj1, df_obj2], axis=1, join='inner'))
运行结果:
A B C D
a 1.0 1.0 NaN NaN
b 1.0 3.0 NaN NaN
c 9.0 0.0 NaN NaN
a NaN NaN 8.0 6.0
b NaN NaN 3.0 6.0
A B C D
a 1 1 8 6
b 1 3 3 6
三、数据重构
1. stack
将列索引旋转为行索引,完成层级索引,DataFrame->Series
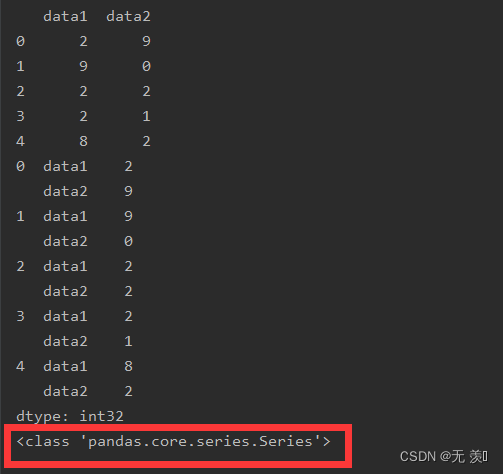
示例代码:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
print(df_obj)
stacked = df_obj.stack()
print(stacked)
print(type(stacked))
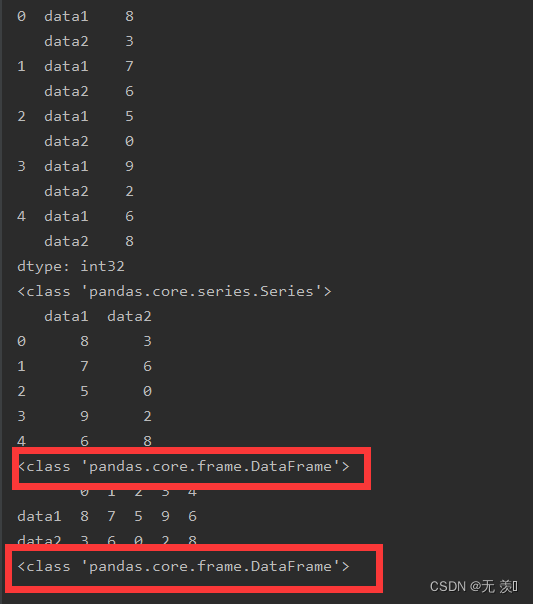
运行结果:DataFrame转换成了Series
2. unstack
将层级索引展开,Series->DataFrame,认操作内层索引,即level=-1
示例代码:
# 默认操作内层索引
df1 = stacked.unstack()
print(df1)
print(type(df1))
# 通过level指定操作索引的级别
df2 = stacked.unstack(level=0)
print(df2)
print(type(df2))
运行结果: