【CMU15-445 Part-8】Tree Indexes ii
Part08-Tree Indexes ii
B+ Tree maintain duplicate indexes
B+ Tree如果维护重复索引或者重复key呢?两种方式解决
- 自动让每个key都变得unique,通过往索引中插入的key后面追加它所对应的tuple的record id来做到这点。 key + record ID make key unique。
- 将重复的key存储到overflow的叶子节点上
插入重复的key #6
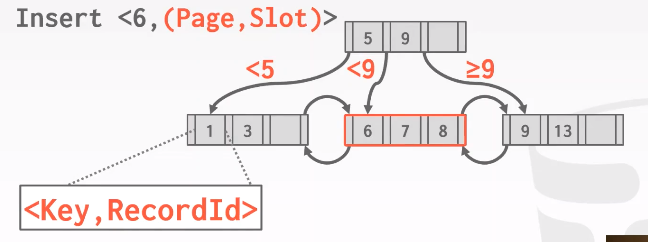
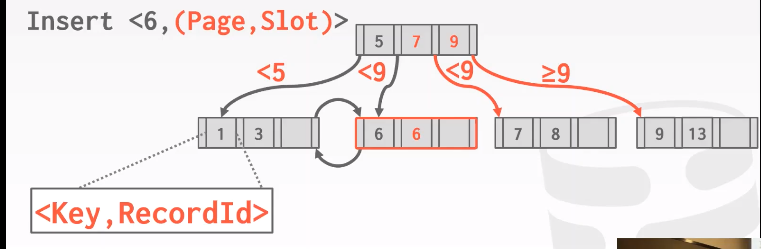
上图是使用key + record ID方法
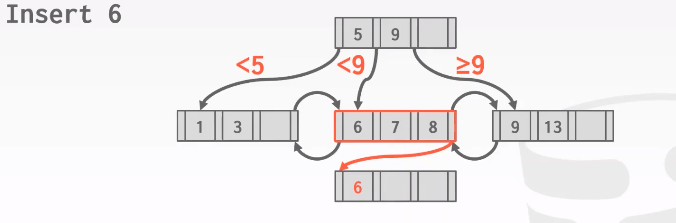
上图是使用over flow page的方法,但是违背了B+ Tree的定义
Demo on Hash and B+ Tree Index
create index idx_emails_hash on emails using hash(email);
;EXPLAIN SELECT * FROM emails WHERE email = '00@00.000'
使用explain返回,index sacn using 什么索引 on eamils
index condtion:((email)::text = ‘00@00.000’::text)
Cluster
CLUSTER emails USING idx_emails_tree
强迫PostgreSQL根据索引定义来对整个表进行重新排序。这个操作只会进行一次,后续删除和插入并不会维护这个顺序。注意这仅仅是对于PG来说是这样的,其它系统会自动cluster
Implicit Indexes
保证主键唯一性约束,当你创建表的时候,下面是等价的:
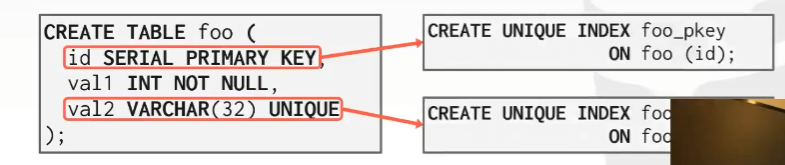
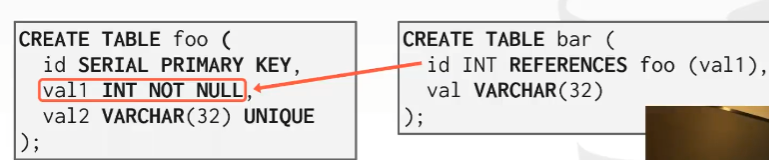
对外键来说,并不是自动创建索引的,下面例子中,创建table bar外键约束到val1,会报错,因为在没有索引的情况下,我们无法强行使用引用完整性约束。
Partial Indexes
不需要整个表上使用索引,只需要某些数据子集。
create index idx_foo on foo(a,b) where c = 'WuTang';
好处:通过使用部分索引避免不需要的数据污染buffer pool,树的高度也会降低,更快查到数据。
Covering Indexes
响应查询需求结果所需的所有字段,都能够在索引本身中找到。不需要专门声明。
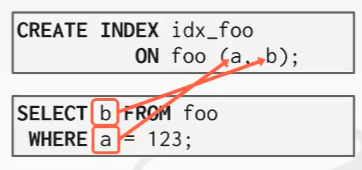
index 中包括了查询需要有关的a,b。不需要查看实际的tuple,就能完成查询。优势:通过page id page表进行查找时,可能需要一次磁盘IO,覆盖索引无需这样去查看底层tuple。
Index Included Columns
CREATE INDEX idx_foo ON foo(a,b) INCLUDE (c);
Functional/Expression Indexes
函数式索引。在声明索引的时候,需要copy tuple的key,放到index里面。但是有些查询不想通过key 的 value来查询,而是通过key所衍生出来的某些数值来查找。
select * from users where extract(dow from login) = 2;
create index idx_user_login on users(login)
create index idx_user_login ON users (EXTRACT(dow FROM login));
create index idx_user_login ON foo(login) Where EXTRACT(dow FROM login) = 2;
PG: select pg_prewarm(’users’); 会预热,即把该表所有数据加载到buffer Pool里面。
Tries Index
radix tree是trie的变式,数据库里面都是用radix tree 不用trie。
trie是树形结构,并不保存key的完整拷贝,而是保存key的digit(key的原子子集,一个bit或者byte)。例子:最后底层叶子节点可以保存record id,指向tuple。
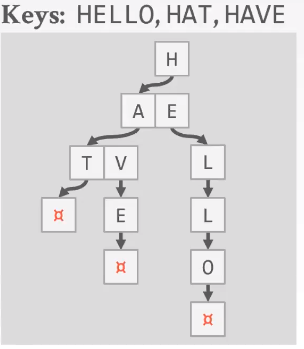
Trie Index Properties
- trie树的形状only取决于key的分布以及长度,不在于插入顺序。
- Trie 不需要 像B+ Tree 重新平衡,可以在垂直方向rebalance
- 操作的复杂度都是O(k),K指的是查找的key的长度。Key隐式地存储在路径里面。
- 向上走 向下走,但是不利于横向的循序扫描,所以点查询来说Tries比B+ Tree快很多,但是扫描的话要回溯很多。
Trie Key Span
span:树枝向外分叉的个数,即树在每一层每个节点中digit的个数。
fan out:最多有多少条way。
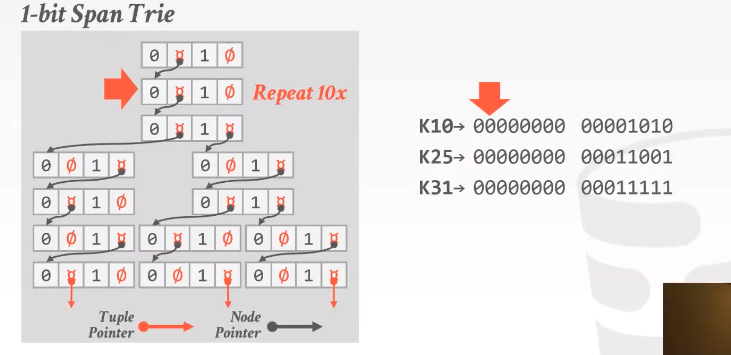
0|pointer|1|null,意味着没有从1走的路径。
优化空间1:根据offset来决定他是0or1
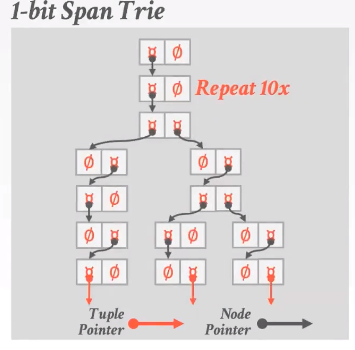
优化空间2:垂直压缩,向下走也就只有那一个了,可以在分支的时候就end。只用一个child,Patricia Tree。
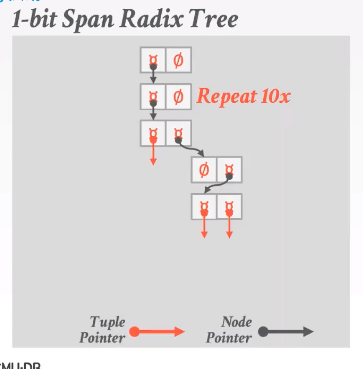
Radix Tree:: Modifications
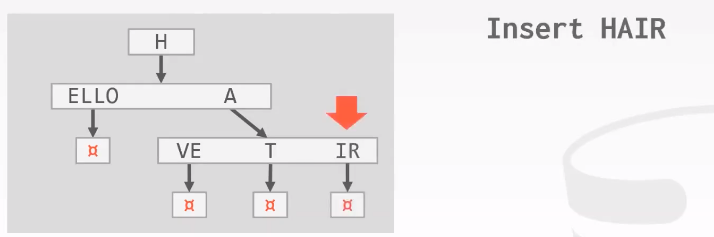
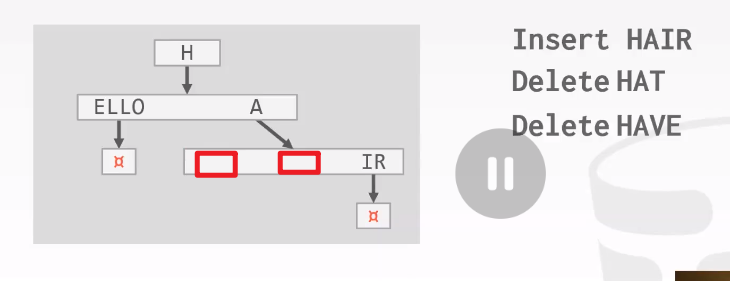
可以先留着空slot,然后再合并。
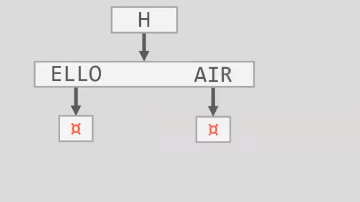
Radix Tree是一种移除了所有可以忽略的路径的Trie树。
WikiPedia Example
B+ Tree and Hash 进行关键词搜索效果不好。因为找的是那些东西的子集,B+ Tree只能用准确的key查找,不能用部分key查找,同理hash。
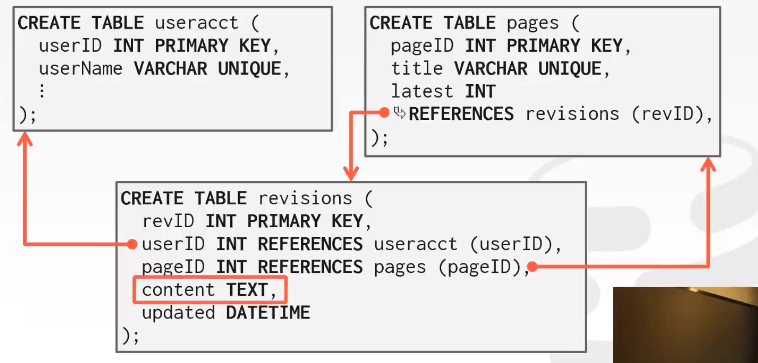
直接在content上建立索引肯定是bad的。
select pageID from revisions Where content like '%Pavlo%';
Inverted Index
可以进行在倒排索引里面的查询有
- Phrase Searches:词组搜索,例如找到所有包含单词pavlo的record
- Proximity Searches:近似搜索,在n words中出现的,关注于上下文。
- Wildcard Searches:利用正则表达式等等。