后端存储实战课——高速增长篇
数据库超时
MySQL CPU 的利用率一直是 100% 的话,MySQL 基本属于不可用的状态,执行的 SQL 都会超时。
CPU 利用率高的情况,绝大多数是由于慢 SQL 引起的,可以通过分析慢 SQL 日志查找类似问题原因。由于数据库忙的时候,执行的 SQL 都很慢,所以慢 SQL 日志中的 SQL 不一定都是有问题的,不能简单通过执行次数和执行时长进行判断,但是要关注单词执行时间特别长的 SQL。
给编写 SQL 带来的启示:
- SQL 涉及的表是哪些,数据规模如何?
- SQL 遍历的数据量是多少?
- 避免写出慢 SQL
给系统设计带来的启示:
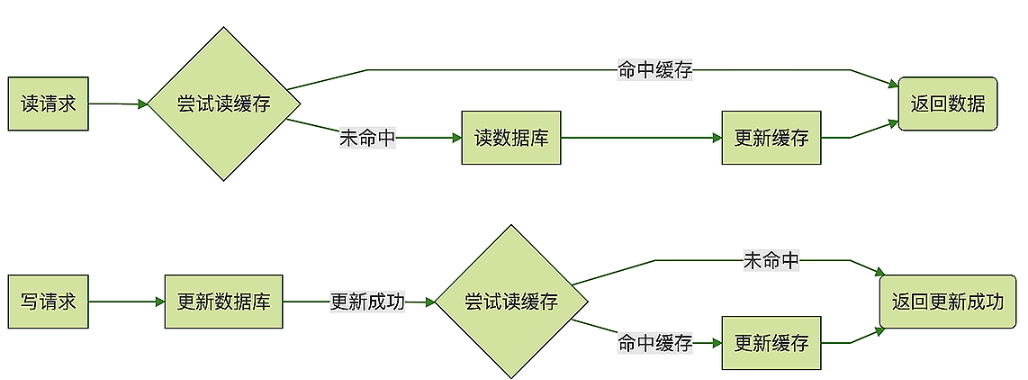
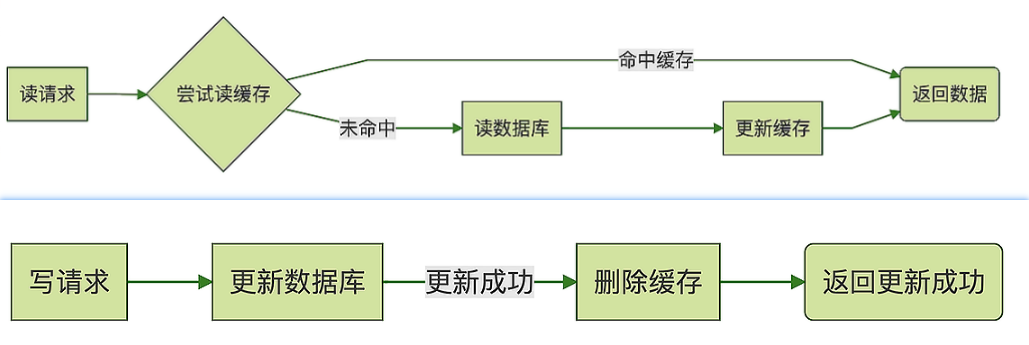
- 利用缓存减少数据库查询,使用缓存时注意缓存命中率(击穿、穿透、雪崩现象)
- 做好监控,及时处理
- 做好降级方案
慢 SQL
一个前提:查询的执行时长基本上是和遍历的数据行数正相关的。
影响 MySQL 处理能力的因素:服务器配置、数据量大小、参数配置、繁忙程度。一台 MySQL 数据库,处理能力的极限大概是每秒一万条简单的 SQL(根据主键查询不需要遍历很多条记录的 SQL),一般一台 MySQL 服务器,平均每秒中执行的 SQL 数量在几百左右就算繁忙了。
一些经验:
- 如果遍历行数在百万以内的,只要不是每秒钟都要执行几十上百次的频繁查询,可以认为是安全的。遍历数据行数在几百万的,查询时间最少也要几秒钟,你就要仔细考虑有没有优化的办法。遍历行数达到千万量级和以上的,这种查询就不应该出现在你的系统中。当然我们这里说的都是在线交易系统,离线分析类系统另说。
- 遍历行数在千万左右,是 MySQL 查询的一个坎儿。MySQL 中单个表数据量,也要尽量控制在一千万条以下,最多不要超过二三千万这个量级。原因也很好理解,对一个千万级别的表执行查询,加上几个 WHERE 条件过滤一下,符合条件的数据最多可能在几十万或者百万量级,这还可以接受。但如果再和其他的表做一个联合查询,遍历的数据量很可能就超过千万级别了。所以,每个表的数据量最好小于千万级别。
如果真需要遍历大量数据,两种方案:
- 使用索引避免全表扫描(增加索引的代价是降低数据插入、删除、更新的性能,对于更新频繁并且对更新性能要求高的表尽量少建索引),关联阅读:MySQL 索引入门、MySQL 查询优化
- 分析 SQL 的执行计划,关联阅读:MySQL explain 使用
缓存使用
更新策略简单贴图,雪崩、击穿、穿透问题不再赘述
Read/Write Through:
Cache Aside:
Write Back:Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
MySQL 读写分离
步骤
部署一主多从 MySQL 实例
参考 MySQL 官方文档
分离应用对数据库的读写请求
- 手动实现,在 DAO 层做修改
- 使用 Sharding-JDBC 组件(代码侵入少)
- 代理方式:在应用程序和数据库实例之间部署一组数据库代理实例,比如说 Atlas 或者 MaxScale。对应用程序来说,数据库代理把自己伪装成一个单节点的 MySQL 实例,应用程序的所有数据库请求被发送给代理,代理分离读写请求,然后转发给对应的数据库实例。(会加长请求的链路,有一定性能损失)
主从延迟
- 如果有插入后立马要求查询到的业务,可以直连主库查询
- MySQL 的并行复制
- 业务上规避(在应用程序和数据库实例之间部署一组数据库代理实例,比如说 Atlas 或者 MaxScale。对应用程序来说,数据库代理把自己伪装成一个单节点的 MySQL 实例,应用程序的所有数据库请求被发送给代理,代理分离读写请求,然后转发给对应的数据库实例)
MySQL 主从
大概步骤
MySQL 可以通过修改配置的方式来更改下述的时序。
主库需要执行的操作:
- 提交事务
- 更新存储的数据
- 写 binlog
- 向客户端返回响应
- 将 binlog 复制到所有从库
从库需要做的:
- 将上述的 binlog 暂存
- 回放 binlog
- 更新对应数据
- 向主库发送复制成功的响应
复制方式
默认情况下,MySQL 采用的是异步复制的方式,因此执行事务操作的线程不会等待复制 binlog 的线程。
异步复制:主库向客户端返回操作成功的响应后,从库中会有专门线程从主库接收 binlog,并将其保存到中继日志中。从库中还有专门用来回放 binlog 的线程,读取中继日志,回收 binlog,更新数据
同步复制:同步复制的时序和异步复制基本是一样的,唯一的区别是,什么时候给客户端返回响应。异步复制时,主库提交事务之后,就会给客户端返回响应;而同步复制时,主库在提交事务的时候,会等待数据复制到所有从库之后,再给客户端返回响应。
半同步复制:异步复制是,事务线程完全不等复制响应;同步复制是,事务线程要等待所有的复制响应;半同步复制介于二者之间,事务线程不用等着所有的复制成功响应,只要一部分复制响应回来之后,就可以给客户端返回了。
海量数据导致存储系统慢
拆,将一大坨数据拆分成 N 个小坨,学名「分片」。
归档历史数据
将大量的不常用的历史数据移到另外一张历史表中,大概流程:
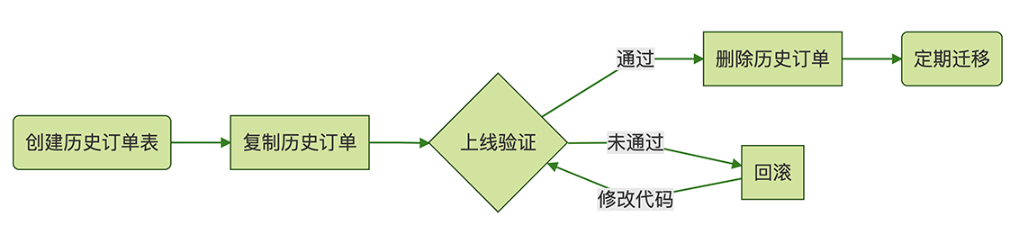
批量删除大量数据
不能一次性直接删除,需要分批删除(并在每次删除之间停一会儿):
delete from orderswhere timestamp < SUBDATE(CURDATE(),INTERVAL 3 month)order by id limit 1000;
优化思路:先查出来符合条件的 id,然后根据 id 去删除:
select max(id) from orders
where timestamp < SUBDATE(CURDATE(),INTERVAL 3 month);
delete from orders
where id <= ?
order by id limit 1000;
删除数据后表空间没有被释放原因:虽然逻辑上每个表是一颗 B+ 树,但是物理上,每条记录都是存放在磁盘文件中的,这些记录通过一些位置指针来组织成一颗 B+ 树。当 MySQL 删除一条记录的时候,只能是找到记录所在的文件中位置,然后把文件的这块区域标记为空闲,然后再修改 B+ 树中相关的一些指针,完成删除。其实那条被删除的记录还是躺在那个文件的那个位置,所以并不会释放磁盘空间。
解决方案:可以执行一次 OPTIMIZE TABLE 释放存储空间。对于 InnoDB 来说,执行 OPTIMIZE TABLE 实际上就是把这个表重建一遍,执行过程中会一直锁表,也就是说这个时候下单都会被卡住,这个是需要注意的。前提条件是 MySQL 的配置必须是每个表独立一个表空间(innodb_file_per_table = ON),如果所有表都是放在一起的,执行 OPTIMIZE TABLE 也不会释放磁盘空间。