//希尔排序-升序
void ShellSort(int* a, int n)
{
int gap = n;//初始化gap为n
while (gap > 1)//控制步数
{
gap = gap / 2; //每一次步数缩小两倍
for (int i = 0; i < n - gap; ++i)//控制区间
{
int end = i;//有序序列最后一个元素下标
int keyi = a[i + gap];//待插入元素
while (end >= 0)//控制有序序列范围
{
if (a[end] > keyi)
{
a[end + gap] = a[end];
}
else
{
break;
}
end -= gap;
}
a[end + gap] = keyi;
}
}
}
//直接选择排序(双指针)-升序
void SelectSort(int* a, int n)
{
int left = 0, right = n - 1;//初始化左右区间
while (left < right)
{
int maxi = left, mini = left;//给最大最小指针下标赋初值
for (int i = left; i <= right; ++i)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[left], &a[mini]);//将最小的下标元素换到最前端
if (maxi == left)//如果最小的下标下是最大的元素,那么就矫正最大元素下标防止冲突!
{
maxi = mini;
}
Swap(&a[right], &a[maxi]);//最大元素与最尾端元素交换
++left;//左右区间缩小
--right;
}
}
//冒泡排序-升序
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n; ++i)
{
bool flag = true;
for (int k = 1; k < n - i; ++k)
{
if (a[k - 1] > a[k])
{
Swap(&a[k - 1], &a[k]);
flag = false;
}
}
if (flag)
break;
}
}
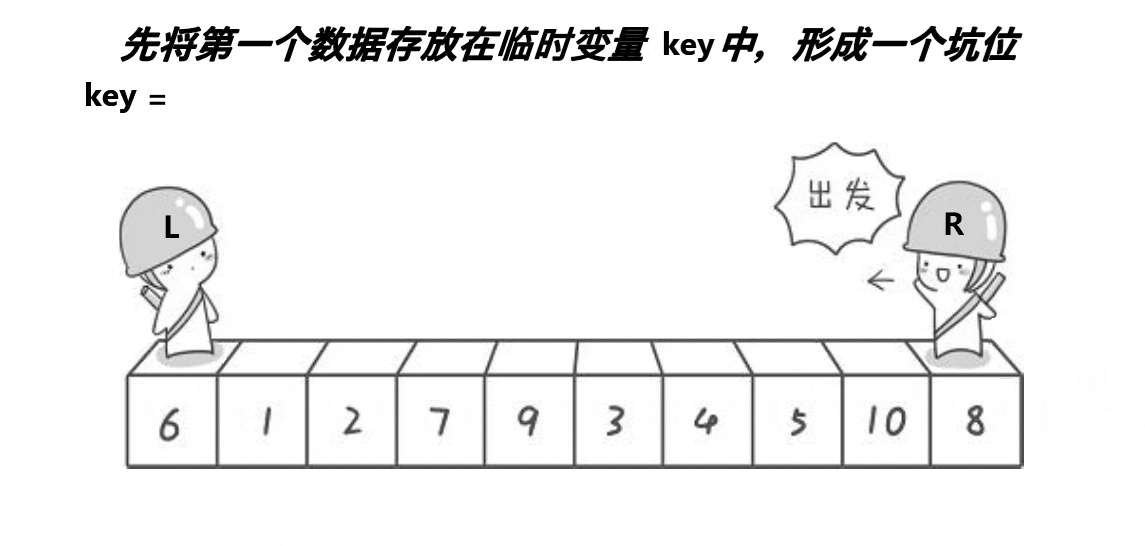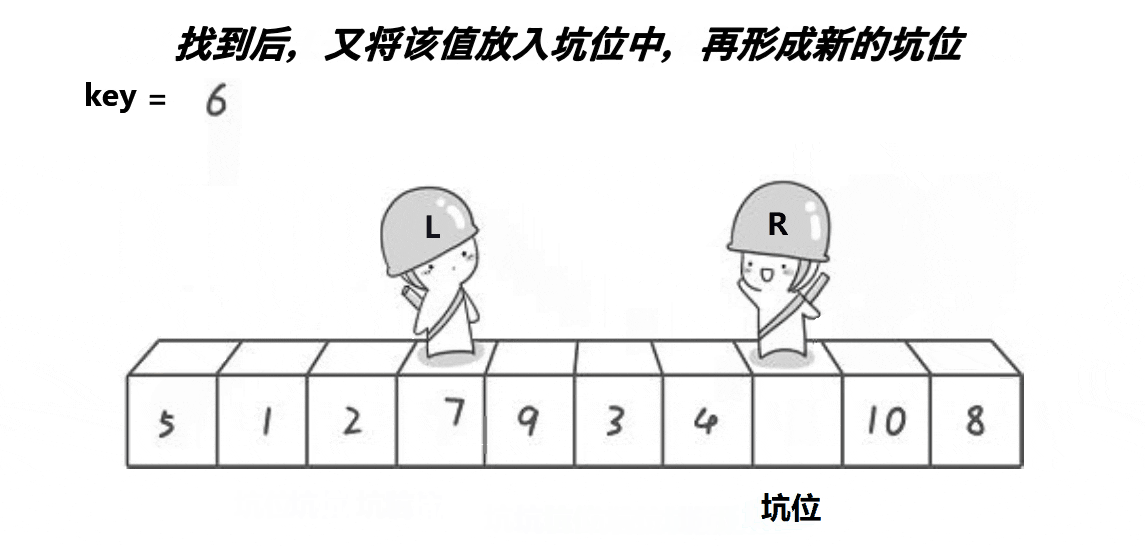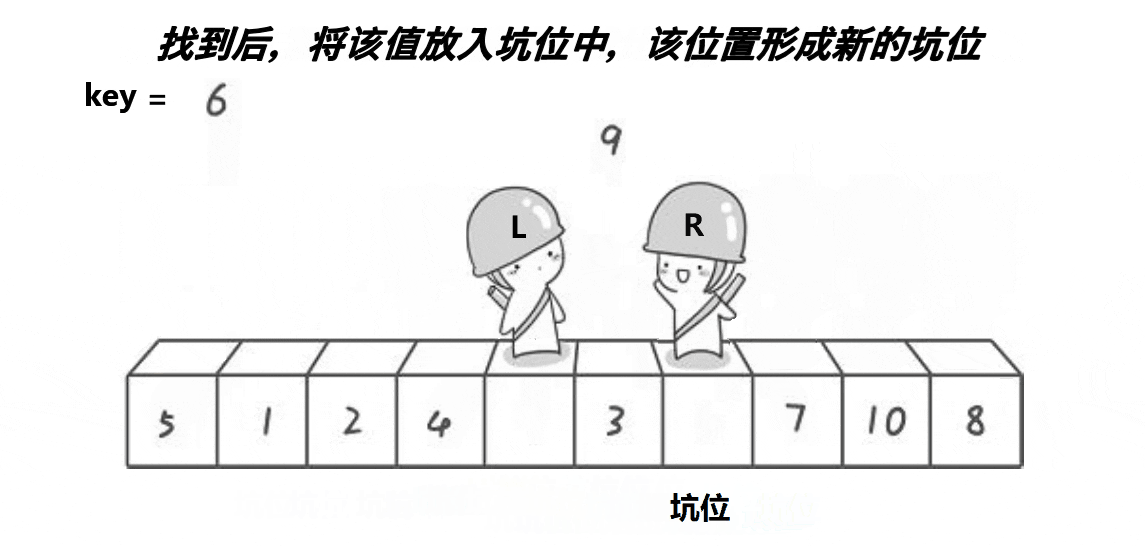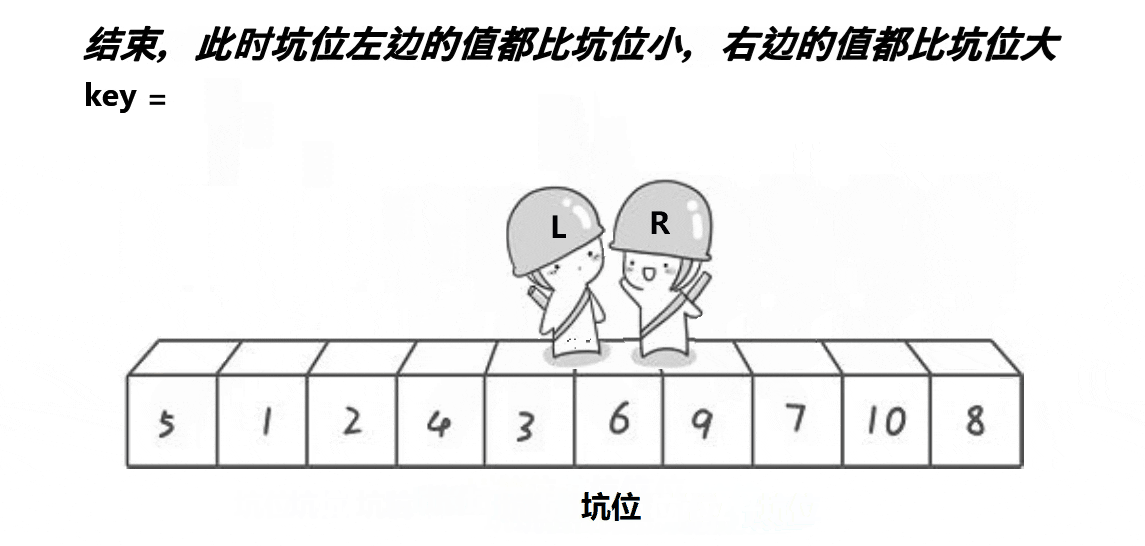
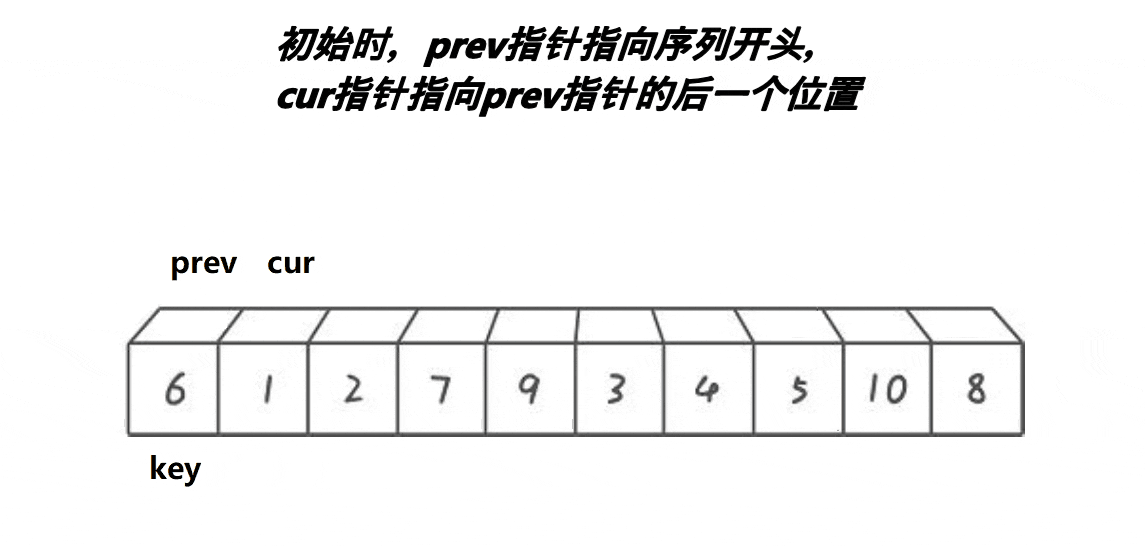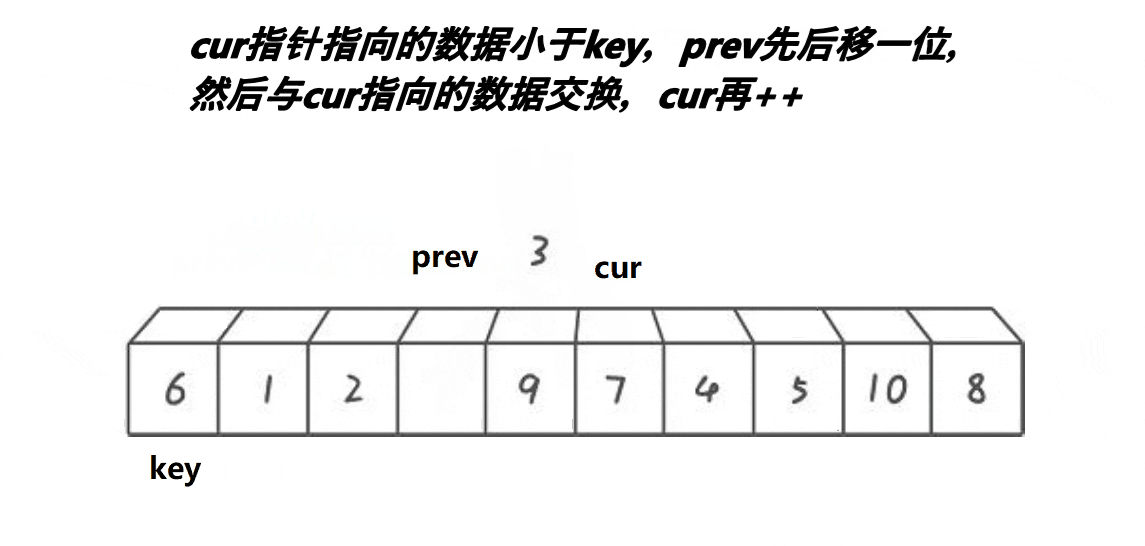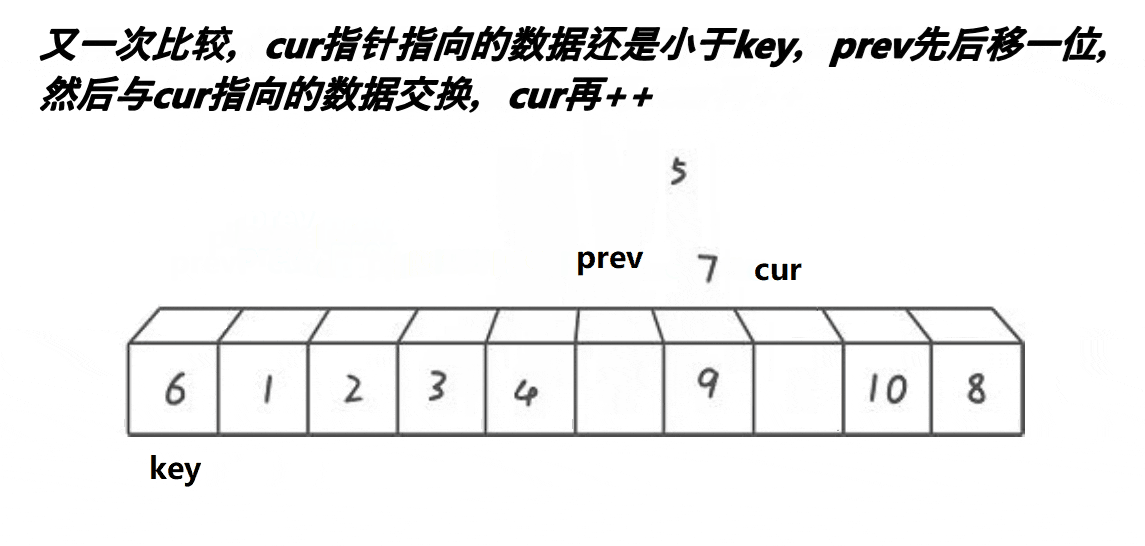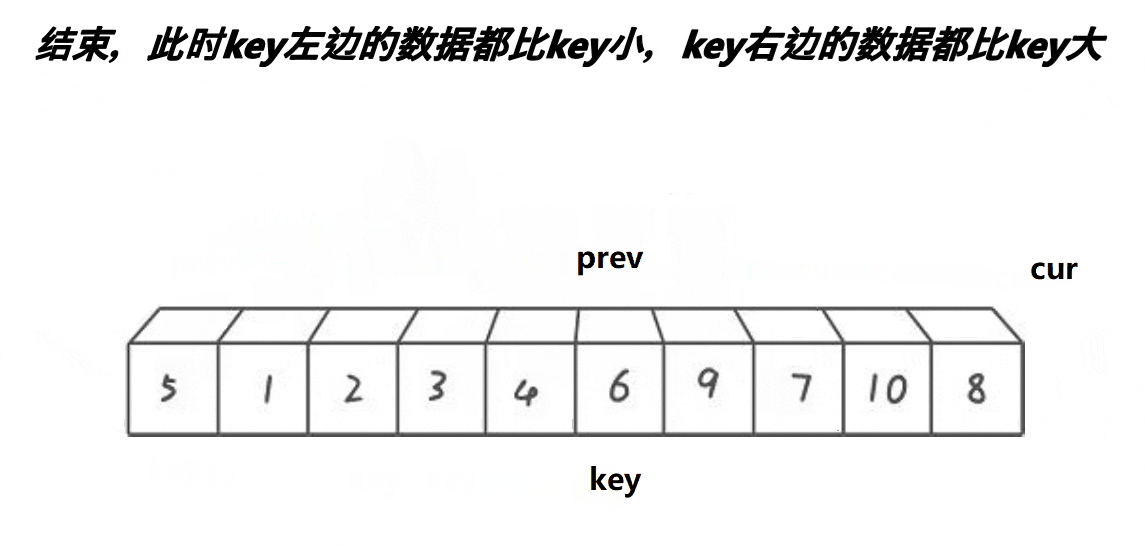
//快速排序-Hoare-升序
void QuickSortHoare(int* a, int head, int end)
{
if (head >= end)//如果区间元素个数为1则停止递归
return;
int left = head, right = end;//取左右序列区间
int keyi = left;//取头元素下标
while (left < right)//开始调整排序
{
while (left < right && a[right] >= a[keyi])//右(尾)指针开始移动找比key小的
{
--right;
}
while (left < right && a[left] <= a[keyi])//当右指针找到了,左(头)指针开始移动找比key大的
{
++left;
}
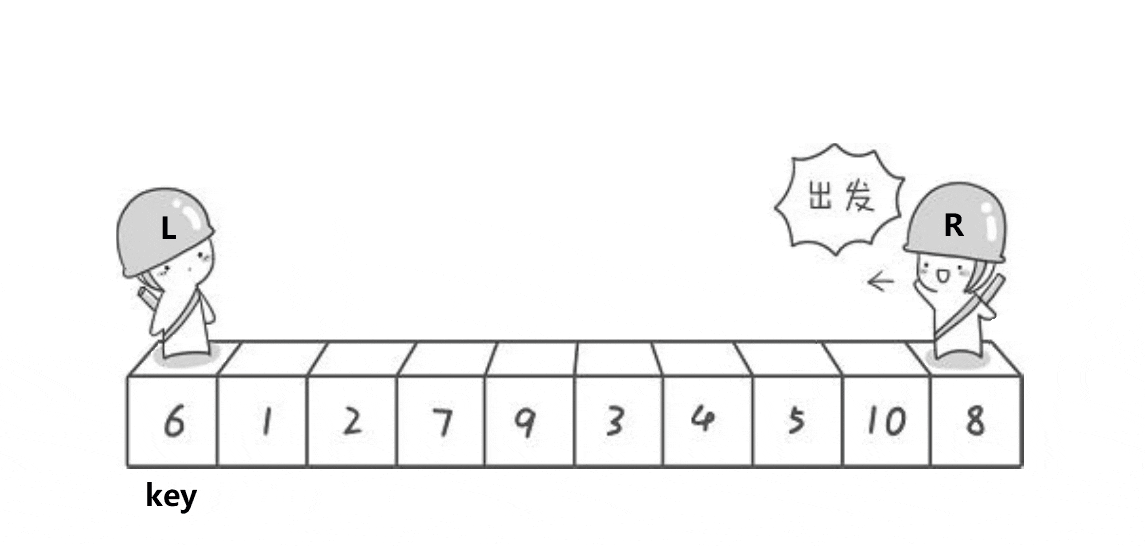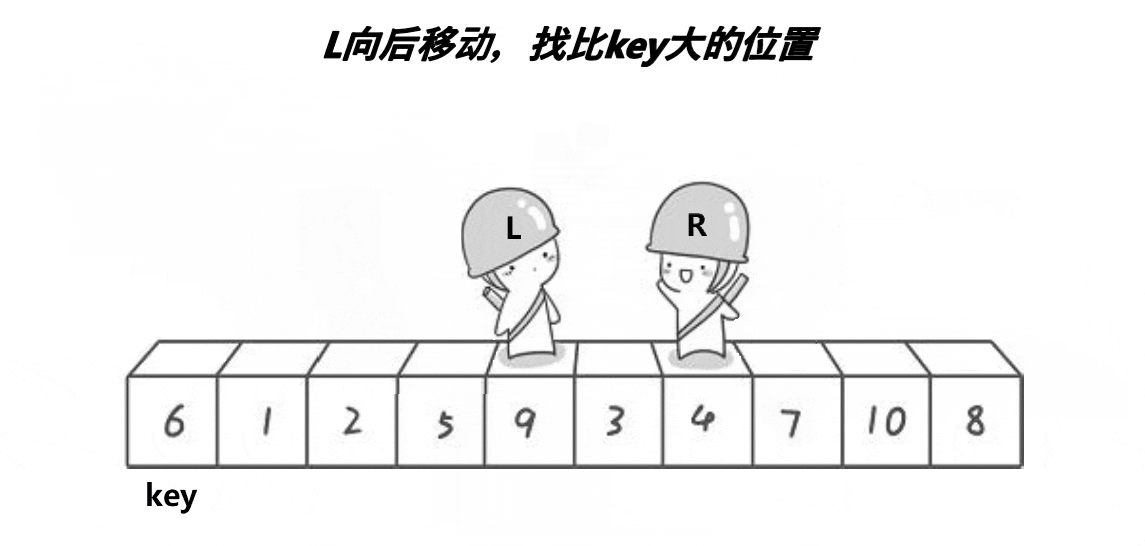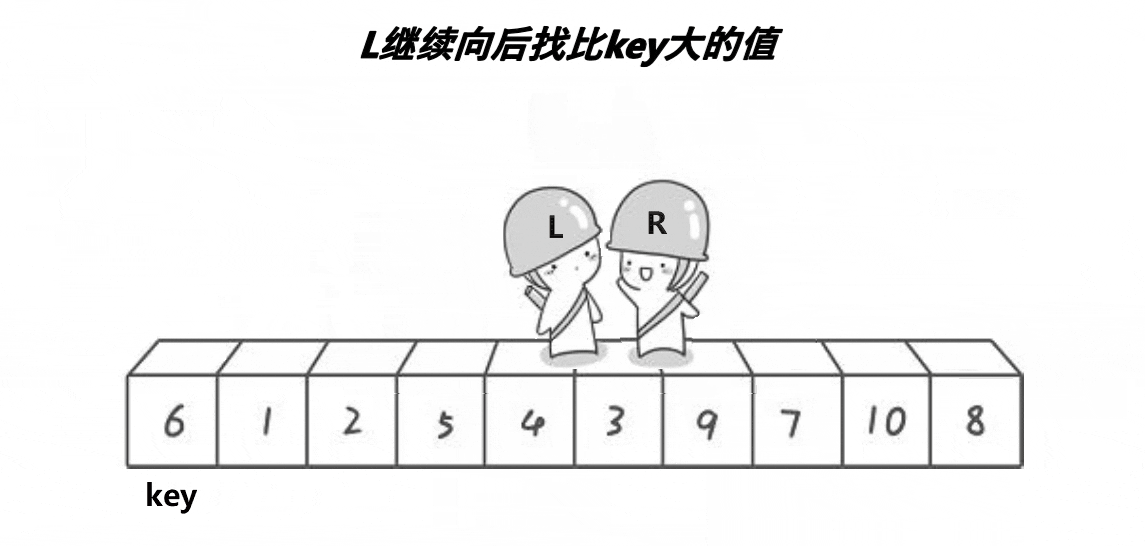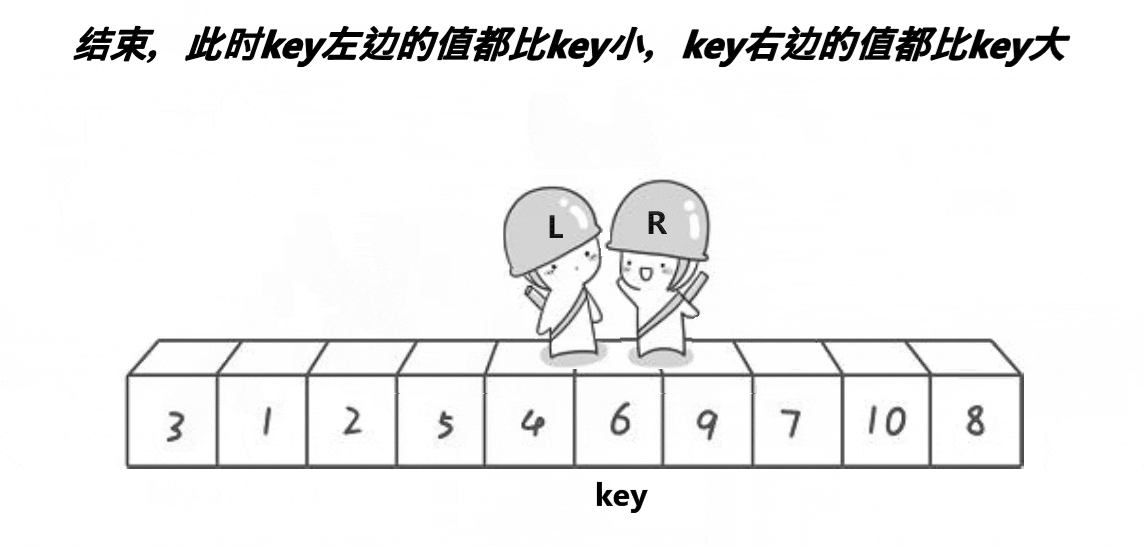
Swap(&a[left], &a[right]);//两个都找到了就相互交换
}
Swap(&a[left], &a[keyi]);//最后将key与相遇下标元素交换
//这样最终key左边的都是比key小的,右边都是比key大的且key被放到了他的排序位上
QuickSortHoare(a, head, left - 1);//递归对分开的两个区间继续排序
QuickSortHoare(a, right + 1, end);
}
//快速排序非递归版-升序
void QuickSortNonR(int* a, int head, int end)
{
Stack st;//定义栈
StackInit(&st);//初始化栈
StackPush(&st, end);//右区间入栈
StackPush(&st, head);//左区间入栈
while (!StackEmpty(&st))//栈不为空继续迭代
{
int left = StackTop(&st);//左区间先出栈存入left中
int l = left;//l再存储一次方便后面对比产生的区间是否合法
StackPop(&st);//左区间下标出栈
int right = StackTop(&st);//右区间先出栈存入right中
int r = right;//r再存储一次方便后面对比产生的区间是否合法
StackPop(&st);//右区间下标出栈
int keyi = left;//确定当前区间序列的一个key
while (left < right)//霍尔法快速排序
{
while (left < right && a[right] >= a[keyi])
{
--right;
}
while (left < right && a[left] <= a[keyi])
{
++left;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
if (right + 1 < r)//如果右区间+1没有超出当前区间则存入当前右区间
{
StackPush(&st, r);
StackPush(&st, right + 1);
}
if (left - 1 > l)
{
StackPush(&st, left - 1);//如果左区间-1没有超出当前区间则存入当前左区间
StackPush(&st, l);
}
}
StackDestroy(&st);//排序完成后销毁栈
}
//快速排序最终优化版-升序
void QuickSort(int* a, int head, int end)
{
if (head >= end)//如果区间相遇则停止递归
return;
if ((end - head + 1) <= 15)//如果区间数据小于15个则改用直接插入排序
{
InsertSort(a + head, end - head + 1);
}
else
{
int left = head;
int right = end;
int cur = left + 1;
Swap(&a[left], &a[GetMidIndex(a, head, end)]);//三数取中并将中性数据放置中序列头
int keyi = a[left];
while (cur <= right)//三段划分
{
if (a[cur] < keyi)
{
Swap(&a[cur++], &a[left++]);
}
else if (a[cur] > keyi)
{
Swap(&a[cur], &a[right--]);
}
else if (a[cur] == keyi)
{
++cur;
}
}
QuickSortMaxDup(a, head, left - 1);
QuickSortMaxDup(a, right + 1, end);
}
}
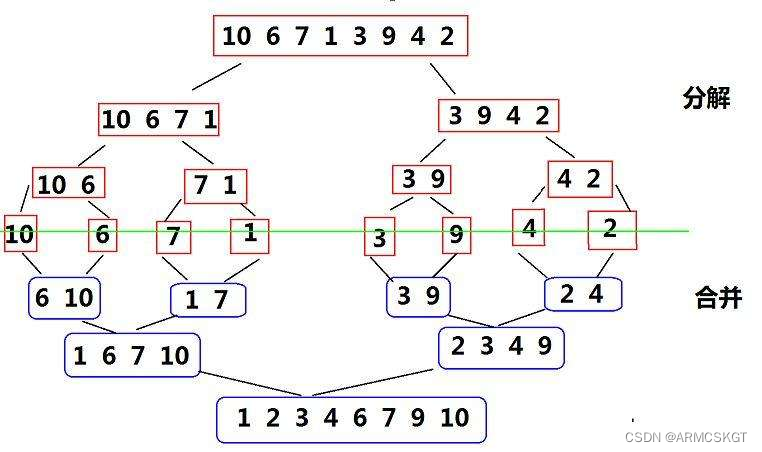
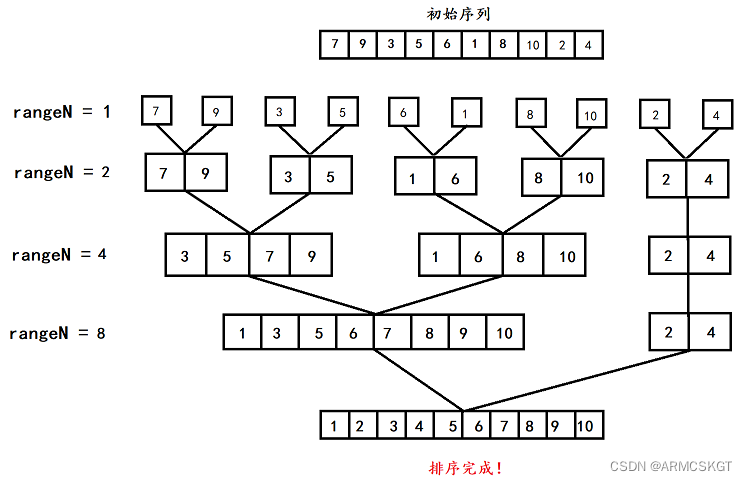
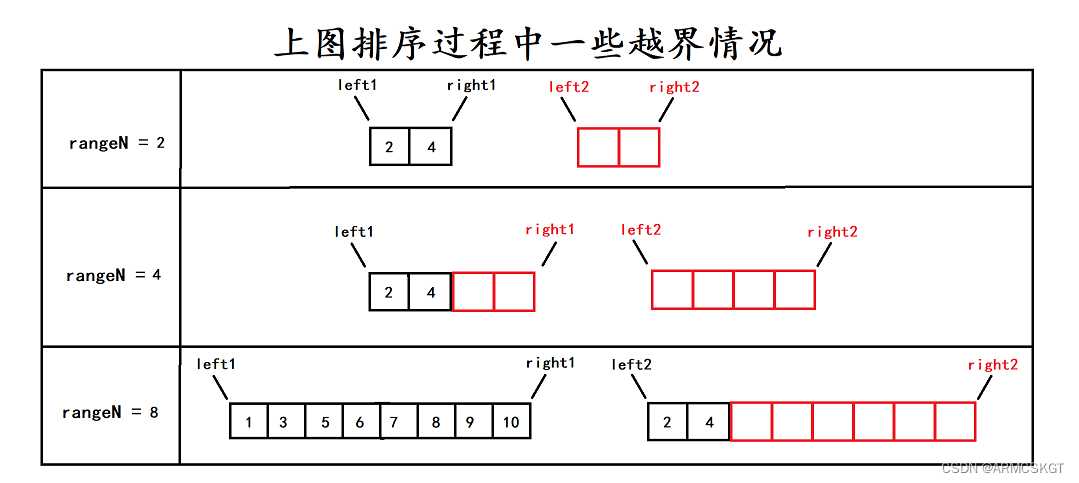
代码思路:在开始排序之前,归并排序函数需要一个数组tmp作为临时排序数组,定义一个mid变量将序列头尾下标head和end相加除2得到中间下标,于是就分为了两个区间,[head,mid],[mid+1,end],对这个区间继续以以上方式递归分解,直到分为一个数元素区间时停止开始归并排序,此时有两个区间,分别由left1和right1以及left2和right2来接收,然后开始合并两个区间,两有序区间从left1和left2开始比较,如果left1下标下的元素小则先放在tmp数组上,然后tmp数组指针 i 指向下一个位置,然后继续比较,直到一个序列走完或者两个序列全部走完。此时我们并不知道两个序列是否都走完,使用两个while循环判断,如果有序列没有走完则将序列上的元素依次拷贝到tmp数组上,两个区间合并完成使用memcpy拷贝到原序列的指定区间上即可!
//二路归并排序-升序
void MergeSort(int* a, int* tmp, int head, int end)
{
if (head >= end)//如果区间为一个元素则停止递归
return;
int mid = (head + end) / 2;//取中间下标
MergeSort(a, tmp, head, mid);//对产生的两个区间开始递归
MergeSort(a, tmp, mid+1, end);
//递归完成后开始合并序列
int left1 = head,right1 = mid;
int left2 = mid + 1, right2 = end;
int i = head;//记录当前两个序列合并后的头下标分别对tmp数组进行相对位置赋值
while (left1 <= right1 && left2 <= right2)//两个序列进行归并
{
if (a[left1] < a[left2])//比较两序列元素,小的放入tmp数组中
{
tmp[i++] = a[left1++];
}
else
{
tmp[i++] = a[left2++];
}
}
while (left1 <= right1)//检查区间释放全部走完
{
tmp[i++] = a[left1++];
}
while (left2 <= right2)
{
tmp[i++] = a[left2++];
}
//将tmp数组上合并好的序列拷贝到原序列上的指定区间位置
memcpy(a + head, tmp + head, sizeof(int) * (end - head + 1));
}
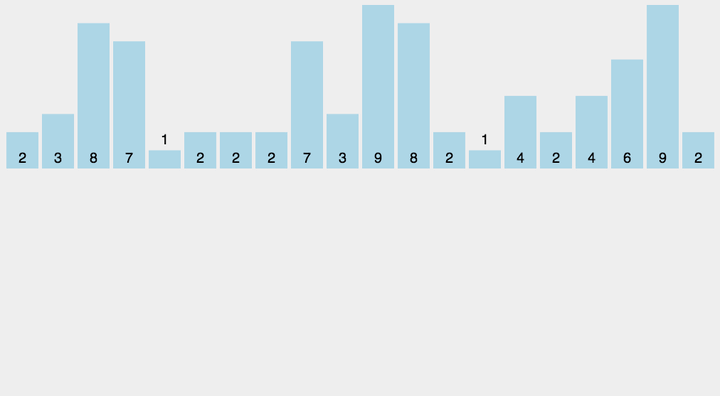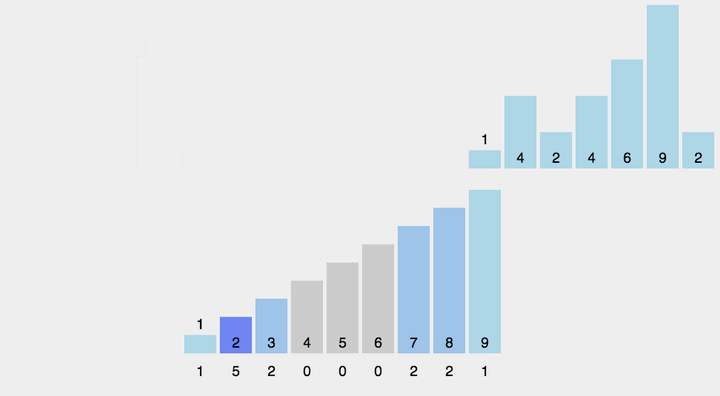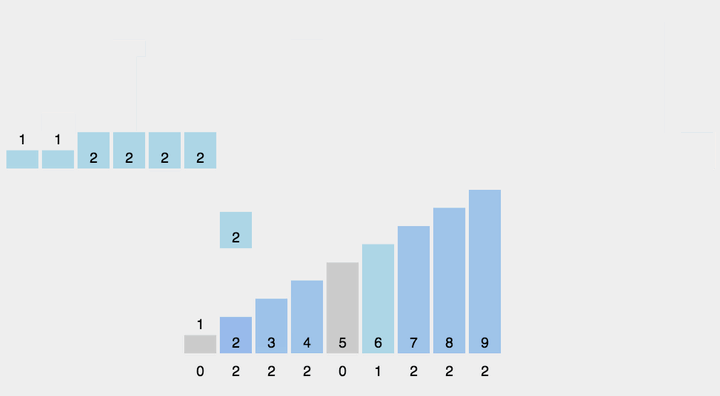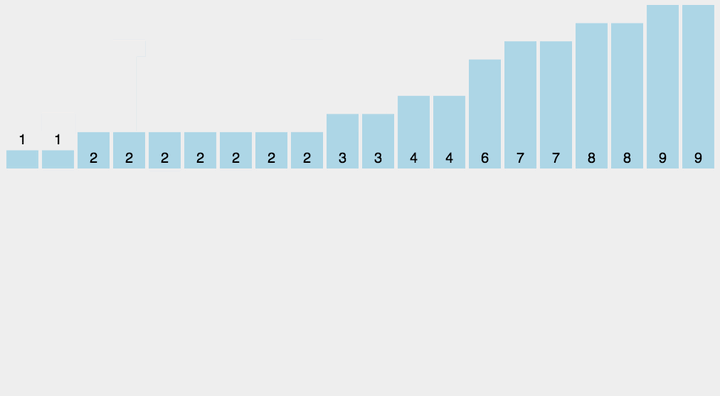
//计数排序
void CountSort(int* a, int n)
{
int maxi = a[0], mini = a[0];//初始化最大最小值
for (int i = 0; i < n; ++i)//找最大最小值
{
if (a[i] > maxi)
{
maxi = a[i];
}
if (a[i] < mini)
{
mini = a[i];
}
}
//根据最大最小值之差开辟辅助数组
int range = maxi - mini + 1;
int* tmp = (int*)calloc(range, sizeof(int));
if (!tmp)
exit(EOF);
//将序列映射到辅助数组tmp上
for (int i = 0; i < n; ++i)
{
tmp[a[i] - mini]++;
}
//将辅助数组上的值通过计算填充到原序列上
for (int i = 0, k = 0; i < range; ++i)
{
while (tmp[i]--)
{
a[k++] = i + mini;
}
}
}
)。

)。


)。
)。
)
