爬虫报错:twisted.web._newclient.ResponseNeverReceived
我在使用scrapy进行数据爬取的过程中,出现了标题所示的报错信息。一开始以为是自己xpath路径写的有问题,然而没有用。于是百度搜索,以为是爬取频率略高被识别了,换了ip,还是报错,终于在github上找到了解决办法,这里仅供参考,因为每个人遇到的具体情况存在差异,只有不断尝试才知道怎么解决。(原贴详见蓝色链接)
简单来说,就是cryptography就是捆绑了 libssl,因此需要降低版本以便顺利连接过时的服务器。实测降低pyOpenSSL和cryptography至图二版本即可
问题提出:
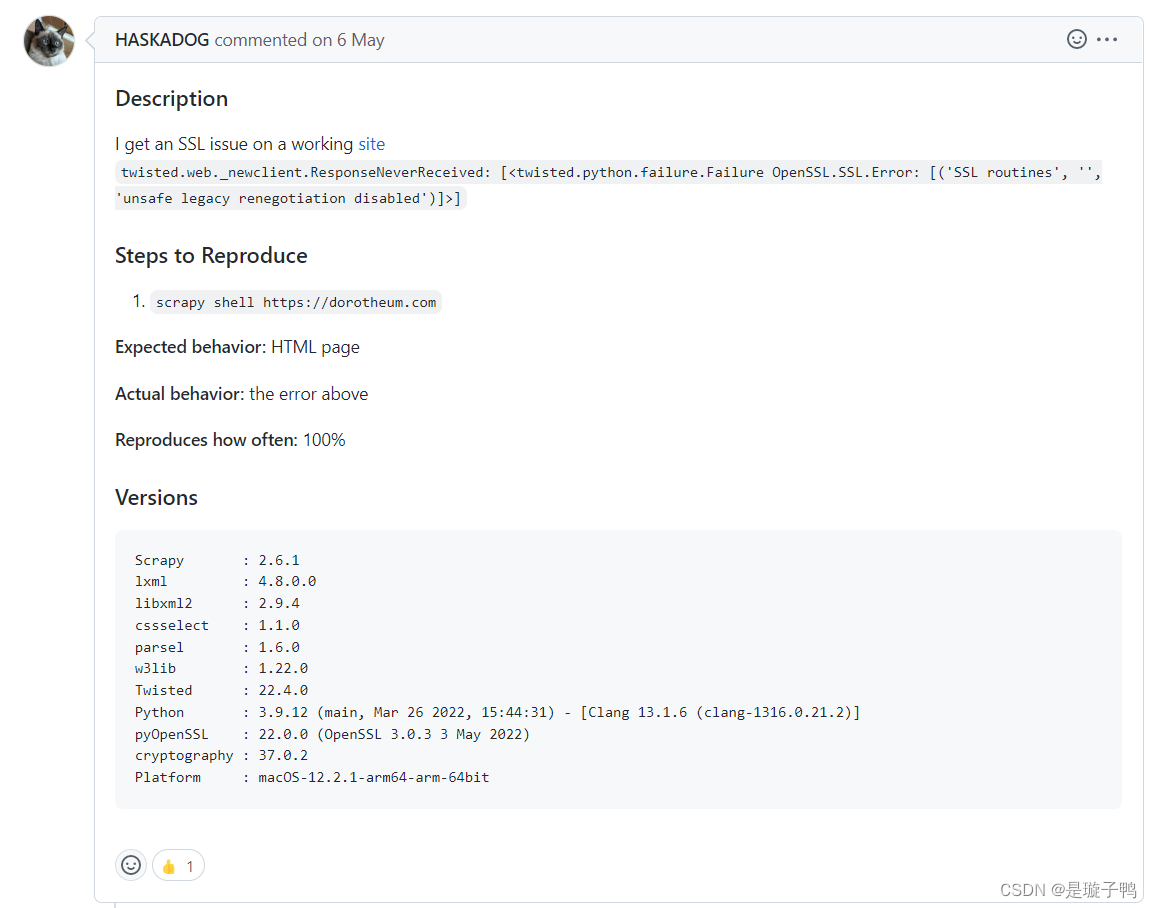
对比(修改后,主要看版本数↓)
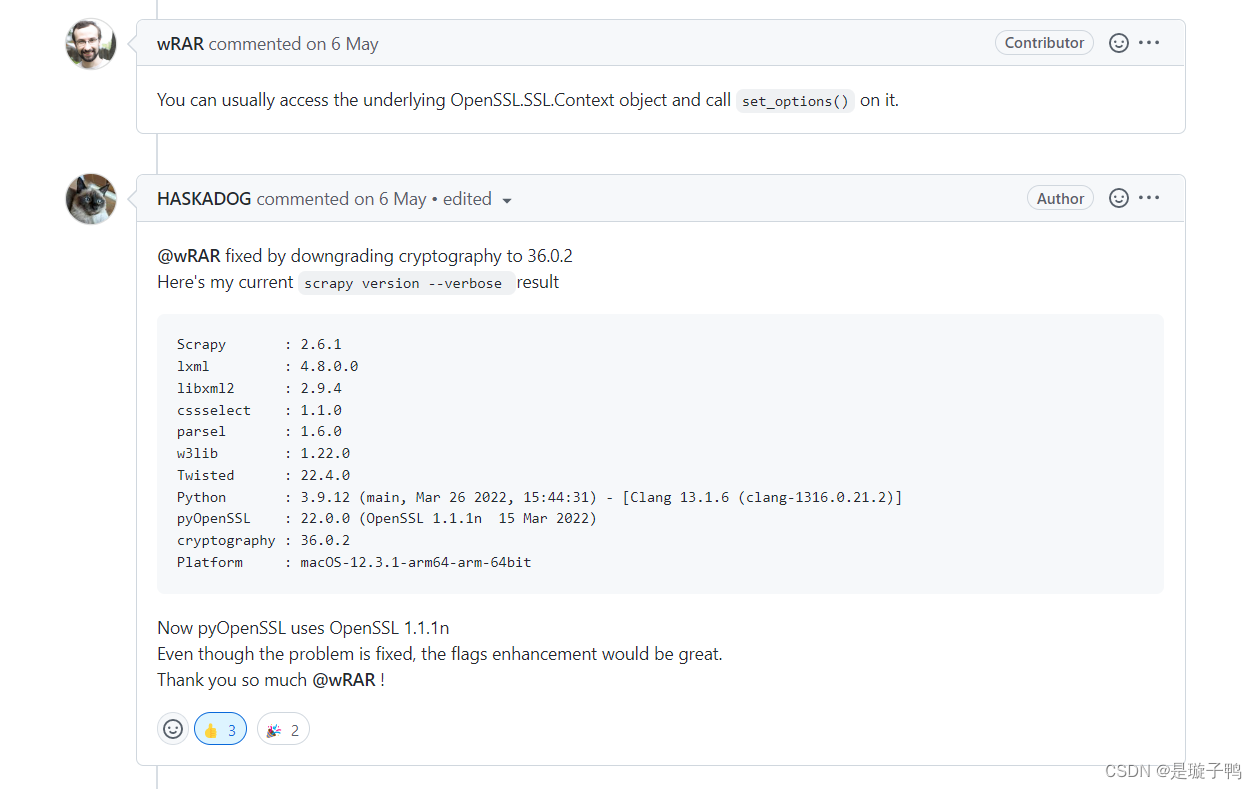
实测降低pyOpenSSL和cryptography至图二版本即可
响应成功!!