机器学习:详细推导高斯混合聚类(GMM)原理(附Python实现)
目录
- 0 写在前面
- 1 高斯概率密度
- 2 混合高斯分布
- 3 GMM算法
- 3.1 定义
- 3.2 参数估计
- 4 Python实现
- 4.1 算法流程
- 4.2 E步
- 4.3 M步
- 4.4 可视化
0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。强基计划实现从理论到实践的全面覆盖,由本人亲自从底层编写、测试与文章配套的各个经典算法,不依赖于现有库,可以大大加深对算法的理解。
🚀详情:机器学习强基计划(附几十种经典模型源码)
1 高斯概率密度
高斯分布又叫正态分布,是一个在理科、工科、文科等多个领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力,具有:
- 集中性:正态曲线的高峰位于正中央
- 对称性:正态曲线以均值为中心,左右对称
- 均匀性:正态曲线从均值处开始,分别向左右两侧逐渐均匀下降
高斯分布的表达式是
f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) f\left( x \right) =\frac{1}{\sqrt{2\pi}\sigma}\exp \left( -\frac{\left( x-\mu \right) ^2}{2\sigma ^2} \right) f(x)=2πσ1exp(−2σ2(x−μ)2)
其中 μ \mu μ是均值, σ \sigma σ是标准差
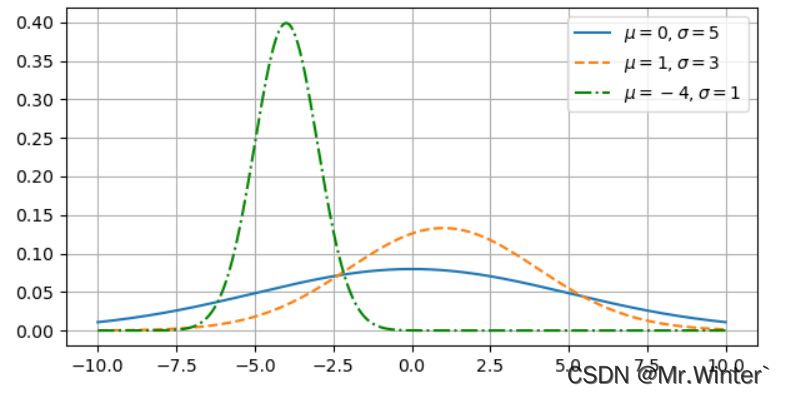
2 混合高斯分布
混合高斯模型(Gaussian Mixture Model)是通过一定的权重将多个单高斯分布加权而成的混合概率模型,使模型容量更大,产生更复杂的采样或拟合更复杂的分布。
混合高斯分布的表达式很容易理解:
p M ( x ) = ∑ j = 1 k π j P ( x ∣ μ j , Σ j ) p_{\mathcal{M}}\left( \boldsymbol{x} \right) =\sum_{j=1}^k{\pi _jP\left( \boldsymbol{x}|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right)} pM(x)=j=1∑kπjP(x∣μj,Σj)
其中 ∑ j = 1 k π j = 1 \sum_{j=1}^k{\pi _j}=1 ∑j=1kπj=1,将第一节的三个高斯分布以一定权重加权得到下图所示的混合高斯分布
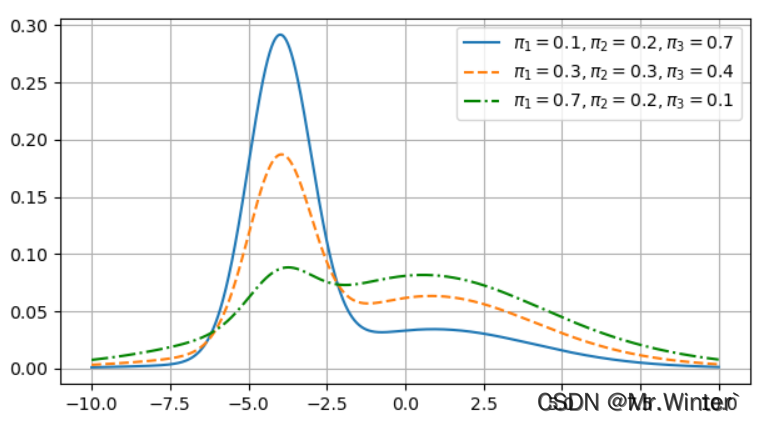
3 GMM算法
3.1 定义
高斯混合聚类基于极大似然法,采用一组原型分布来刻画数据聚合结构。在基于原型向量的原型聚类中,与原型向量最接近的样本被划分为簇;在GMM中,则将最有可能由原型分布产生的样本划分为簇
样本 x \boldsymbol{x} x符合上述的混合高斯分布
p M ( x ) = ∑ j = 1 k P ( x , z ∣ μ j , Σ j ) = ∑ j = 1 k P ( z ∣ μ j , Σ j ) P ( x ∣ μ j , Σ j ) p_{\mathcal{M}}\left( \boldsymbol{x} \right) =\sum_{j=1}^k{P\left( \boldsymbol{x},z|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right)}=\sum_{j=1}^k{P\left( z|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) P\left( \boldsymbol{x}|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right)} pM(x)=j=1∑kP(x,z∣μj,Σj)=j=1∑kP(z∣μj,Σj)P(x∣μj,Σj)
其中 P ( x ∣ μ j , Σ j ) P\left( \boldsymbol{x}|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) P(x∣μj,Σj)为高斯分布
P ( x ∣ μ j , Σ j ) = 1 ( 2 π ) d / 2 ∣ Σ j ∣ 1 / 2 exp ( − 1 2 ( x − μ j ) T Σ j − 1 ( x − μ j ) ) P\left( \boldsymbol{x}|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) =\frac{1}{\left( 2\pi \right) ^{{{d}/{2}}}\left| \boldsymbol{\varSigma }_j \right|^{{{1}/{2}}}}\exp \left( -\frac{1}{2}\left( \boldsymbol{x}-\boldsymbol{\mu }_j \right) ^T\boldsymbol{\varSigma }_{j}^{-1}\left( \boldsymbol{x}-\boldsymbol{\mu }_j \right) \right) P(x∣μj,Σj)=(2π)d/2∣Σj∣1/21exp(−21(x−μj)TΣj−1(x−μj))
隐变量 z i z_i zi为样本 x \boldsymbol{x} x所属的簇标记,也是我们要学习的参数。 P ( x ∣ μ j , Σ j ) P\left( \boldsymbol{x}|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) P(x∣μj,Σj)与 P ( z ∣ μ j , Σ j ) P\left( z|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) P(z∣μj,Σj)独立,因为隐式地为 x \boldsymbol{x} x赋予标记不会影响 x \boldsymbol{x} x由某个高斯分布分量 N j ( μ j , Σ j ) N_j\left( \boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) Nj(μj,Σj)产生的概率。进一步,定义由 N j ( μ j , Σ j ) N_j\left( \boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) Nj(μj,Σj)产生样本的簇标记就为 j j j,即 P ( z ∣ μ j , Σ j ) = P ( z = j ) P\left( z|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right) =P\left( z=j \right) P(z∣μj,Σj)=P(z=j),记为 α \alpha α。混合高斯分布简化为
p M ( x ) = ∑ j = 1 k α j P ( x ∣ μ j , Σ j ) p_{\mathcal{M}}\left( \boldsymbol{x} \right) =\sum_{j=1}^k{\alpha _jP\left( \boldsymbol{x}|\boldsymbol{\mu }_j,\boldsymbol{\varSigma }_j \right)} pM(x)=j=1∑kαjP(x∣μj,Σj)
其中 ∑ j = 1 k α j = 1 \sum\nolimits_{j=1}^k{\alpha _j}=1 ∑j=1kαj=1
3.2 参数估计
对于模型参数待估计且隐变量分布未知的情形,采用EM算法迭代求解。这部分的推导请看机器学习强基计划6-4:详细推导期望最大化EM算法及收敛性分析(附实例),通过EM算法可以得到
μ j = ∑ i = 1 m γ i j x i ∑ i = 1 m γ i j {\boldsymbol{\mu }_j=\frac{\sum\nolimits_{i=1}^m{\gamma _{ij}\boldsymbol{x}_i}}{\sum\nolimits_{i=1}^m{\gamma _{ij}}}} μj=∑i=1mγij∑i=1mγijxi
Σ j = ∑ i = 1 m γ i j ( x i − μ j ) ( x i − μ j ) T ∑ i = 1 m γ i j {\boldsymbol{\varSigma }_j=\frac{\sum\nolimits_{i=1}^m{\begin{array}{c} \gamma _{ij}\left( \boldsymbol{x}_i-\boldsymbol{\mu }_j \right)\\\end{array}\left( \boldsymbol{x}_i-\boldsymbol{\mu }_j \right) ^T}}{\sum\nolimits_{i=1}^m{\begin{array}{c} \gamma _{ij}\\\end{array}}}} Σj=∑i=1mγij∑i=1mγij(xi−μj)(xi−μj)T
其中 γ i j ( j = 1 , 2 , ⋯ , k ) \gamma _{ij}\left( j=1,2,\cdots ,k \right) γij(j=1,2,⋯,k)是经过E步计算得到的 Q ( z i ) Q\left( \boldsymbol{z}_i \right) Q(zi)
对于 α \alpha α,由于其需要在满足 ∑ j = 1 k α j = 1 \sum\nolimits_{j=1}^k{\alpha _j}=1 ∑j=1kαj=1的前提下最大化似然,因此引入拉格朗日形式
L L ( θ , λ ) = L ( θ ) + λ ( ∑ j = 1 k α j − 1 ) LL\left( \boldsymbol{\theta },\lambda \right) =L\left( \boldsymbol{\theta } \right) +\lambda \left( \sum_{j=1}^k{\alpha _j-1} \right) LL(θ,λ)=L(θ)+λ(j=1∑kαj−1)
其中 λ \lambda λ为拉格朗日算子。令 ∂ L L ( θ , λ ) / ∂ α j = 0 {{\partial LL\left( \boldsymbol{\theta },\lambda \right)}/{\partial \alpha _j}}=0 ∂LL(θ,λ)/∂αj=0,则
∂ L L ( θ , λ ) ∂ α j = ∂ L ( θ ) ∂ α j + λ = ∑ i = 1 m γ i j α j + λ = 0 \frac{\partial LL\left( \boldsymbol{\theta },\lambda \right)}{\partial \alpha _j}=\frac{\partial L\left( \boldsymbol{\theta } \right)}{\partial \alpha _j}+\lambda =\sum_{i=1}^m{\frac{\gamma _{ij}}{\alpha _j}}+\lambda =0 ∂αj∂LL(θ,λ)=∂αj∂L(θ)+λ=i=1∑mαjγij+λ=0
即得 α j = − ∑ i = 1 m γ i j / λ \alpha _j=-\sum\nolimits_{i=1}^m{{{\gamma _{ij}}/{\lambda}}} αj=−∑i=1mγij/λ。注意到等式 ∑ i = 1 m γ i j / α j + λ = 0 \sum\nolimits_{i=1}^m{{{\gamma _{ij}}/{\alpha _j}}}+\lambda =0 ∑i=1mγij/αj+λ=0两边对 k k k个高斯分量求和可得
∑ j = 1 k ∑ i = 1 m γ i j + λ ∑ j = 1 k α j = 0 ⇒ ∑ i = 1 m ∑ j = 1 k γ i j + λ = 0 ⇒ λ = − m \sum_{j=1}^k{\sum_{i=1}^m{\gamma _{ij}}}+\lambda \sum_{j=1}^k{\alpha _j}=0\Rightarrow \sum_{i=1}^m{\sum_{j=1}^k{\gamma _{ij}}}+\lambda =0\Rightarrow \lambda =-m j=1∑ki=1∑mγij+λj=1∑kαj=0⇒i=1∑mj=1∑kγij+λ=0⇒λ=−m
所以
α j = − 1 m ∑ i = 1 m γ i j { \alpha _j=-\frac{1}{m}\sum_{i=1}^m{\gamma _{ij}}} αj=−m1i=1∑mγij
4 Python实现
4.1 算法流程

4.2 E步
gamma = [] # 后验概率 i x j
for i in range(self.m):
gammaSum = 0
for j in range(self.k):
gammaSum = gammaSum + self.alpha[j] * self.__gauss(self.dataSet[i], self.miu[j], self.sigma[j])
for j in range(self.k):
gamma.append(self.alpha[j] * self.__gauss(self.dataSet[i], self.miu[j], self.sigma[j]) / gammaSum)
4.3 M步
- 更新均值向量
for j in range(self.k): miuTemp = np.zeros_like(self.miu[0]) for i in range(self.m): miuTemp = miuTemp + gamma[i * self.k + j] * self.dataSet[i] gammaTemp = gammaTemp + gamma[i * self.k + j] gammaTempList.append(gammaTemp) self.miu[j] = miuTemp / gammaTemp gammaTemp = 0 - 更新协方差矩阵
for j in range(self.k): sigmaTemp = np.zeros_like(self.sigma[0]) for i in range(self.m): sigmaTemp = sigmaTemp + gamma[i * self.k + j] * np.array(self.dataSet[i] - self.miu[j]).reshape([self.dim, 1]) * \ np.array(self.dataSet[i] - self.miu[j]).reshape([1, self.dim]) self.sigma[j] = sigmaTemp / gammaTempList[j] - 更新混合系数
for j in range(self.k): self.alpha[j] = gammaTempList[j] / self.m
和算法流程一一对应,可对照学习加深理解
4.4 可视化
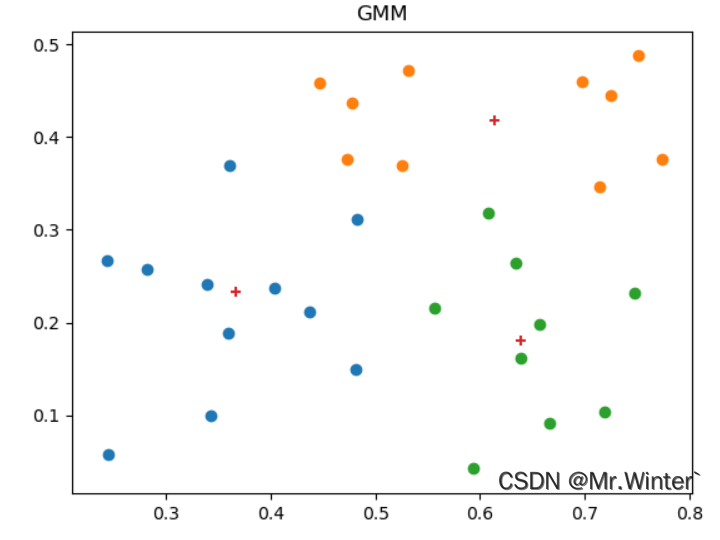
本文完整工程代码联系下方博主名片获取
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《机器人原理与技术》
- 《机器学习强基计划》
- 《计算机视觉教程》
- …